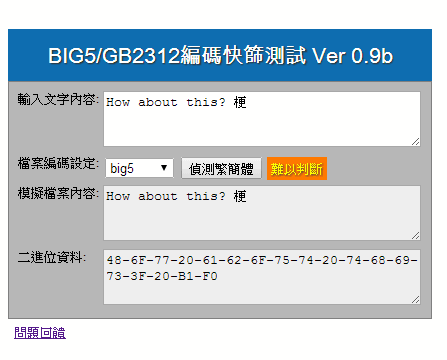
BIG5 與 GB2312 是繁體中文與簡體中文最常採用的 ANSI 形式編碼,當代系統多已改採 Unicode ,但在涉及傳統系統整合的情境中,仍有處理中文 ANSI 編碼的需求。有時,資料來源較雜,BIG5、GB2312 編碼都有可能,系統規劃者多半希望系統能由二進位資料 (Byte Array) 自動判別其編碼為 BIG5 或 GB2312 。就理論而言,以程式判斷 BIG5、GB2312 不可能 100% 精確,理由是二者有部分編碼區段重疊。 例如: 某字元的兩個 Byte 為 0xb1、0xf0,若以 BIG5 編碼解讀為「梗」、以 GB2312 解讀則為「别」,都屬有效字元,此時便無從斷定其編碼。 所幸在實務上,文字內容通常不會只有單一字元,當字元數一多,就有頗高的機會出現某兩個 Byte 在 BIG5 是有效字元,在 GB2312 則否的狀況,反之亦然。 只要掌握這些線索,就有機會實現 BIG5、GB2312 編碼的自動偵測功能,雖無法 100% 精準,已能滿足實務需求。
偵測原理
偵測元件以 .NET 撰寫而成,使用方法很簡單,只需呼叫 int ChEncAutoDetector.Analyze(byte[] data) 傳入二進位資料,程式會分別用 BIG5 與 GB2312 解讀,產生統計資料,計算 ASCII、符號、常用字、次常用字、無效字元的字元數目,並算出亂碼指數 (我稱之為 BadSmell,即無效字元及次常用字佔全部字數的比例,其中無效字元的權重設為次常用字的三倍),接著比較採 BIG5 解碼及採 GB2312 解碼的 BadSmell 何者為高? 當 GB2312 BadSmell 較高時傳回 1,代表該內容為 BIG5 的可能性較高;當 BIG5 BadSmell 較高時傳回-1,代表內容為 GB2312 的可能性較高;若二者的 BadSmell 相同,則意味著程式無從判斷屬何者編碼。 BadSmell 演算法的核心只是簡單的 Byte 比對邏輯,雖然元件以 .NET 開發,但不難改用其他語言實現,而 BadSmell 的計算規則( (無效字元*3 + 次常用字) / 總字元數 )也可依不同使用情境調整參數,但以依初步測試經驗,現值已有相當不錯的準確率。
線上測試
原始碼包含一個網站測試介面( ASP.NET Website Project ),可透過瀏覽器測試中文內容檢測結果,另外亦有線上版。
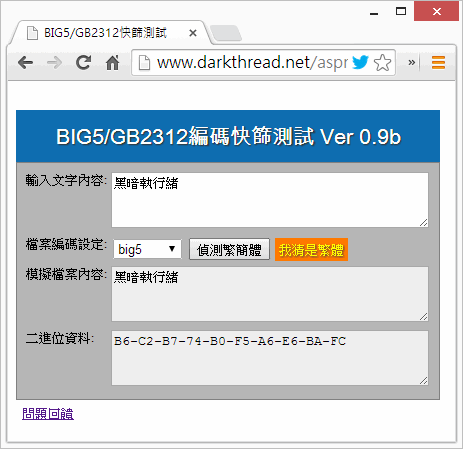
已知限制
由於 BIG5 與 GB2312 的編碼特性,必定存在無法識別甚至誤判的可能性,故應用時請視狀況保留人工複核及事後校正的機制。
無法識別案例:

程式碼下載
https://github.com/darkthread/CEAD